Introduction
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What is the point of these exercises?
How do I find the data I want to work with?
Objectives
To understand why we start with the Open Data Portal
To understand the basics of how the datasets are divided up
Ready to go?
The 3/4 of this lesson is done entirely in the browser.
However, Episode 4: What is in the data files?, requires the use of a running CMSSW environment in the CMS open data Docker container. Make sure you have completed the Docker pre-exercise if your operating system can run the CMSSW container.
You’ve got a great idea! What’s next?
Suppose you have a great idea that you want to test out with real data! You’re going to want to know:
- What year were the data taken that would work best for you?
- In which primary dataset were the data of your interest stored?
- What Monte Carlo datasets are available and appropriate for your studies?
- This may mean finding simulated physics processes that are background to your signal
- This may mean finding simulated physics processes for your signal, if they exist
- Possibly just finding simulated datasets where you know the answer, allowing you to test your new analysis techniques
In this lesson, we’ll walk through the process of finding out what data and Monte Carlo are available to you, how to find them, and how to examine what data are in the individual data files.
What is a Monte Carlo dataset?
You’ll often hear about physicists using Monte Carlo data or sometimes just referring to Monte Carlo. In both cases, we are referring to simulations of different physics processes, which then mimics how the particles would move through the CMS detector and how they might be affected (on average) as they pass through the material. This data is then processed just like the “real” data (referred to as collider data).
In this way, the analysts can see how the detector records different physics processes and best understand how these processes “look” when we analyze the data. This better helps us understand both the signal that we are looking for and the backgrounds which might hide what we are looking for.
First of all, let’s understand how the data are stored and why we need certain tools to access them.
The CERN Open Data Portal
In some of the earliest discussions about making HEP data publicly available there were many concerns about people using and analyzing “other people’s” data. The concern centered around well-meaning scientists improperly analyzing data and coming up with incorrect conclusions.
While no system is perfect, one way to guard against this is to only release well-understood, well-calibrated datasets and to make sure open data analysts only use these datasets. These datasets are given a Digital Object Identifier (DOI) code for tracking. And if there are ever questions about the validity of the data, it allows us to check the data provenance.
DOI
The Digital Object Identifier (DOI) system allows people to assign a unique ID to any piece of digital media: a book, a piece of music, a software package, or a dataset. If you want to learn more about the DOI process, you can learn more at their FAQ. Assigning of DOIs to CERN products is generally handled through Zenodo.
Challenge!
You will find that all the datasets have their DOI listed at the top of their page on the portal. Can you locate where the DOI is shown for this dataset, Record 6029, DoubleElectron primary dataset in AOD format from Run of 2012 (/DoubleElectron/Run2012C-22Jan2013-v1/AOD)
With a DOI, you can create citations to any of these records, for example using a tool like doi2bib.

Provenance
You will hear experimentalists refer to the “provenance” of a dataset. From the Cambridge dictionary, provenance refers to “the place of origin of something”. The way we use it, we are referring to how we keep track of the history of how a dataset was processed: what version of the software was used for reconstruction, what period of calibrations was used during that processing, etc. In this way, we are documenting the data lineage of our datasets.
From Wikipeda
Data lineage includes the data origin, what happens to it and where it moves over time. Data lineage gives visibility while greatly simplifying the ability to trace errors back to the root cause in a data analytics process.
Provenance is an an important part of our data quality checks and another reason we want to make sure you are using only vetted and calibrated data.
This lesson
For all the reasons given above, we encourage you to familiarize yourself with the search features and options on the portal. With your feedback, we can also work to create better search tools/options and landing points.
This exercise will guide you through the current approach to finding data and Monte Carlo. Let’s go!
Key Points
Finding the data is non-trivial, but all the information is on the portal
A careful understanding of the search options can help with finding what you need
Where are the datasets?
Overview
Teaching: 5 min
Exercises: 5 minQuestions
Where do I find datasets for data and Monte Carlo?
Objectives
Be able to find the data and Monte Carlo datasets
CERN Open Data Portal
Our starting point is the landing page for CERN Open Data Portal. You should definitely take some time to explore it. But for now we will select the CMS data.
CERN Open Data Portal
The landing page for the CERN Open Data Portal.
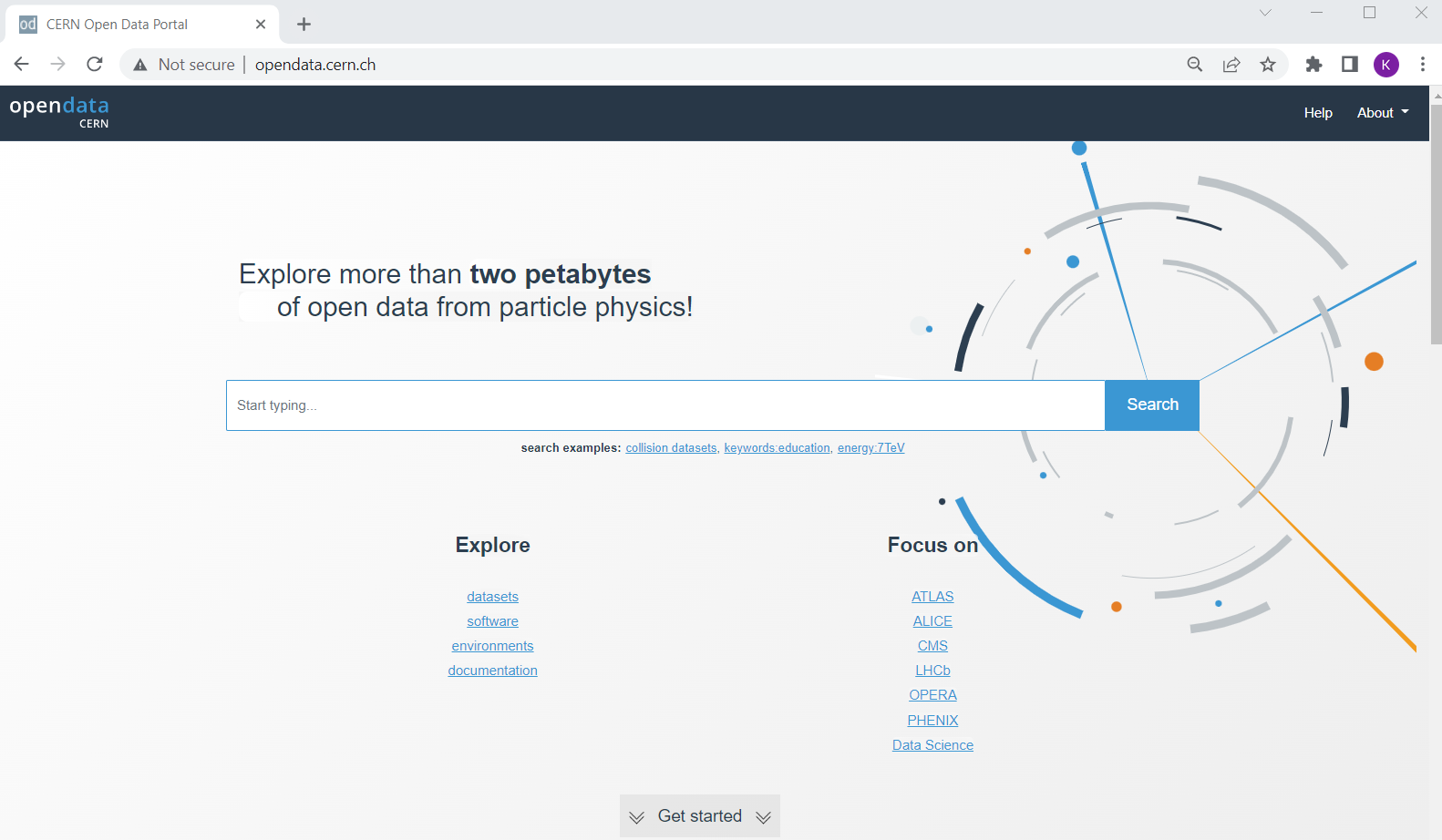
Make a selection!
Find the CMS link under Focus on and click on it.
CMS-specific datasets
The figure below shows the website after we have chosen the CMS data. Note the left-hand sidebar that allows us to filter our selections. Let’s see what’s there. (Note! I’ve collapsed some of the options so while the order is the same when you view it, your webpage may look a little different at first glance.)
CERN Open Data Portal - CMS data
The first pass to filter on CMS data
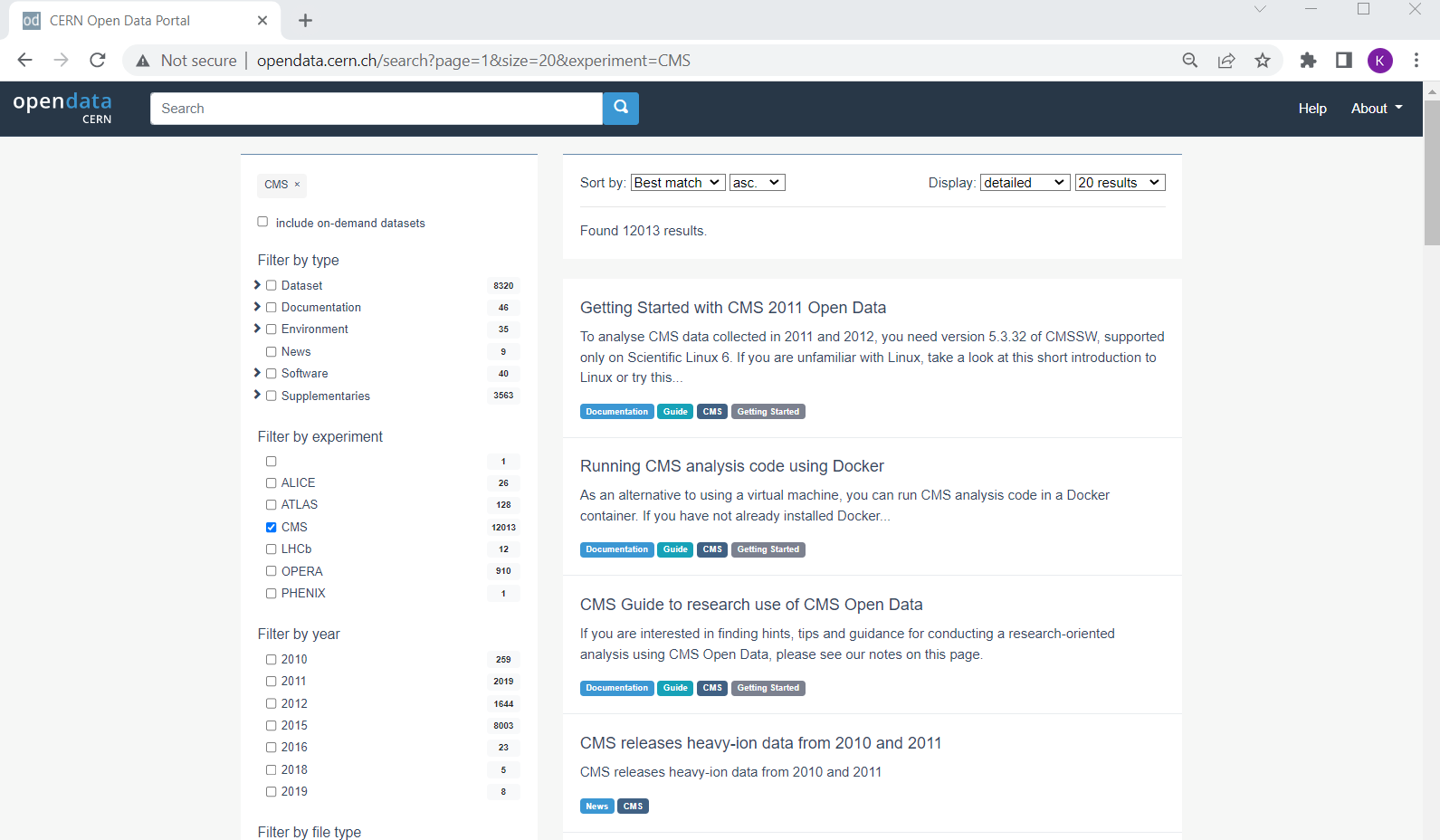
At first glance we can see a few things. First, there is an option to select only Dataset rather than documentation or software or similar materials. Great! Going forward we’ll select Dataset.
Next we see that there are a lot of entries for data from 2010, 2011, 2012, and 2015, the 7 TeV, 8 TeV and 13 TeV running periods. That’s what we’ll be working with for these exercises.
Coming soon!
CMS make regular open data releases, and the next ones are already in preparation.
Make a selection!
For the next module, let’s select Dataset and 2012.
Key Points
Use the filter selections in the left-hand sidebar of the CERN Open Data Portal to find datasets.
What data and Monte Carlo are available?
Overview
Teaching: 5 min
Exercises: 10 minQuestions
What data and run periods are available?
What data do the collision datasets contain?
What Monte Carlo samples are available?
Objectives
To be able to navigate the CERN Open Data Portal’s search tools
To be able to find what collision data and Monte Carlo datasets there are using these search tools
Data and run periods
We make a distinction between data which come from the real-life CMS detector and simulated Monte Carlo data. In general, when we say data, we mean the real, CMS-detector-created data.
The main data available are from what is known as Run 1 and spans 2010-2012. The first batch of Run 2 data from 2015 was released in 2021. These run periods can also be broken into A, B, C, and so-on, sub-periods and you may see that in some of the dataset names.
Make a selection!
If you are coming from the previous module you should have selected CMS, Dataset, and 2012.
CERN Open Data Portal - CMS datasets
Selecting CMS, Dataset, and 2012.
Your view might look slightly different than this screenshot as the available datasets and tools are regularly updated.
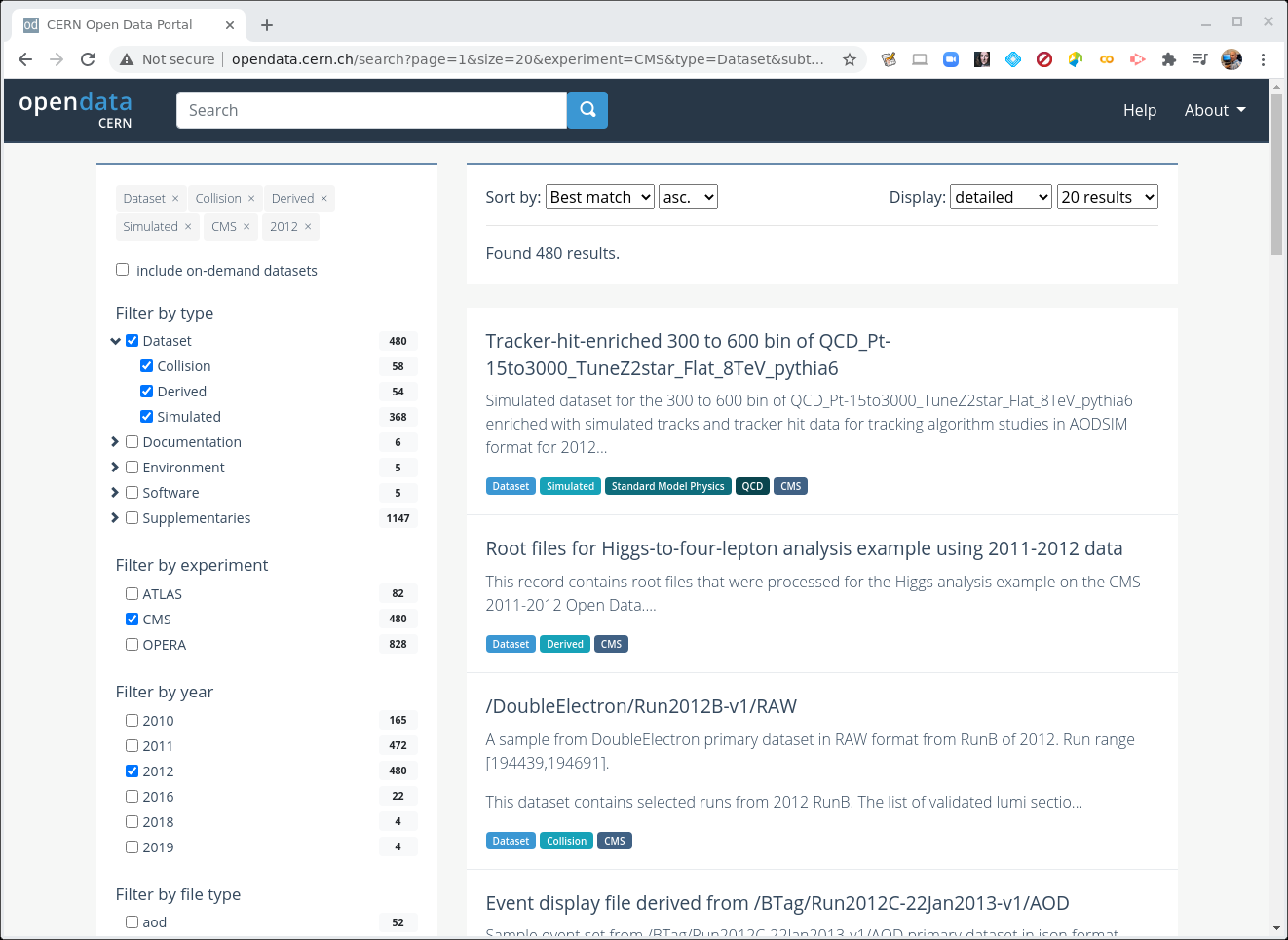
When Dataset is selected, there are 3 subcategories:
- Collision refers to the real data that came off of the CMS detector.
- Derived refers to datasets that have been further processed for some specific purpose, such as outreach and education or the ispy event display.
- Simulated refers to Monte Carlo datasets.
Make a selection!
Let’s now unselect Derived and Simulation so that only the Collision option is set under Dataset.
Collision data
When you select Collision you’ll see a lot of datasets with names that may be confusing. Let’s take a look at two of them and see if we can break down these names.
CERN Open Data Portal - CMS datasets
Some samples from the 2012 collision data
/DoubleElectron/Run2012B-v1/RAW
/SingleMu/Run2012B-22Jan2013-v1/AOD
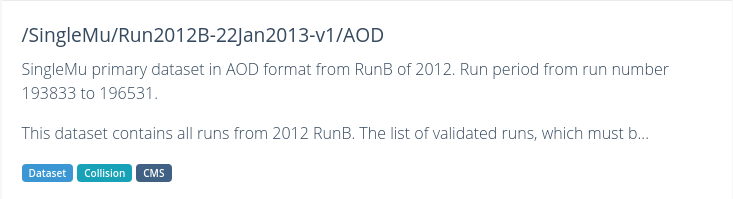
There are three (3) parts to the names, separated by `/’.
Dataset name
DoubleElectron or SingleMu is the name of the dataset. Events stored in these primary datasets were selected by triggers of usually of a same type. For each dataset, the list of triggers is listed in the dataset record. You will learn more about them in the trigger lesson during the workshop, but for now, remind yourself that they select out some subset of the collisions based on certain criteria in the hardware or software.
Some of the dataset names are quite difficult to intuit what they mean. Others should be roughly understandable. For example,
- DoubleElectron contains mainly events with at least two electrons above a certain energy threshold.
- SingleMu contains mainly events with at least one muon above a certain momentum threshold.
- MinimumBias events are taken without any trigger or selection criteria.
Run period
Run2012B-v1 and Run2012B-22Jan2013-v1 refer to when the data were taken and in the case of the second, when the data were processed. The details are not so important for you because CMS only releases vetted data. If you were a CMS analyst working on the data as it was being processed, you might have to shift your analysis to a different dataset once all calibrations were completed.
Data format
- RAW files contain information directly from the detector in the form of hits from the TDCs/ADCs. (TDC refers to to Time to Digital Converter and ADC refers to to Analog to Digital Converter. Both of these are pieces of electronics which convert signals from the components of the CMS detector to digital signals which are then stored for later analysis.) These files are not a focus of this workshop.
- AOD stands for Analysis Object Data. This is the first stage of data where analysts can really start physics analysis.
- MINIAOD is a slimmer format of AOD, in use from Run 2 open data on. Often, the experiment will slim this down and drop some subsets of the data stream into NanoAOD, but the current open data were not yet reprocessed in that format.
Further information
If you click on the link to any of these datasets, you will find even more information, including
- The size of the dataset
- Information on the what is the recommended software release to analyze this dataset
- How were the data selected including the details of the trigger selection criteria. More on this in a later lesson.
- Validation information
- A list of all the individual ROOT files in which this dataset is stored
There are multiple text files that contain the paths to these ROOT files. If we click on any one of them, we see something like this.
CERN Open Data Portal - CMS datasets
Sample listing of some of the ROOT files in the /SingleMu/Run2012B-22Jan2013-v1/AOD dataset.
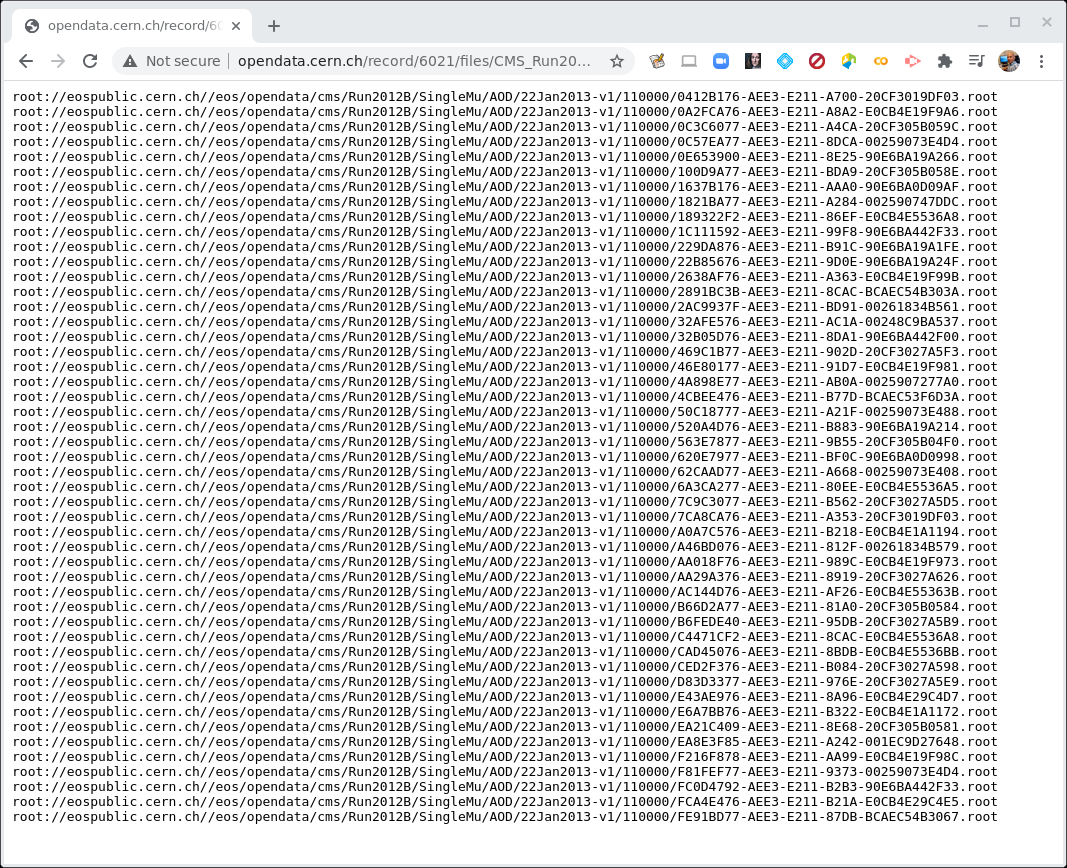
The prepended root: is because of how these files are accessed. We’ll use these directory
paths when we go to inspect some of these files.
Monte Carlo
We can go through a similar exercise with the Monte Carlo data. One major difference is that the Monte Carlo are not broken up by trigger. Instead, when you analyze the Monte Carlo, you will apply the trigger to the data to simulate what happens in the real data. You will learn more about this in the upcoming trigger exercise.
For now, let’s look at some of the Monte Carlo datasets that are available to you.
Make some selections! But first make some unselections!
Unselect everything except for 2012, CMS, Dataset, and Simulated (under Dataset).
Next, select a new button near the top of the left-hand sidebar, include on-demand datasets. This will give us some search options related to the Monte Carlo samples.
CERN Open Data Portal - CMS datasets
Selection of the Monte Carlo dataset search options
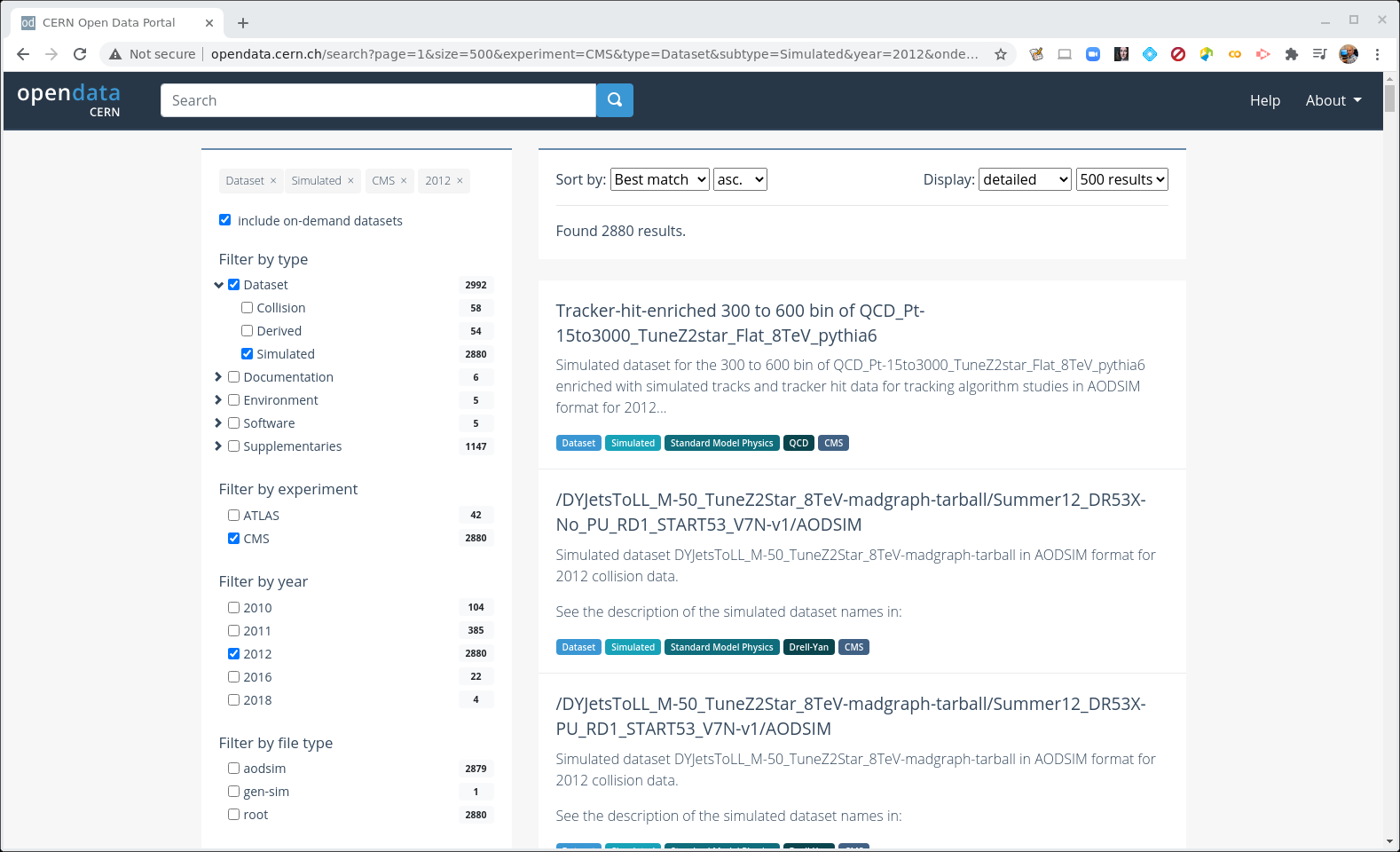
There are a lot of Monte Carlo samples! It’s up to you to determine which ones might contribute to your background. The names try to give you some sense of the primary process, subsequent decays, the beam energy and specific simulation software (e.g. Pythia), but if you have questions, reach out to the organizers through Mattermost.
As with the collision data, here are three (3) parts to the names, separated by `/’.
Let’s look at one of them: /DYJetsToLL_M-50_TuneZ2Star_8TeV-madgraph-tarball/Summer12_DR53X-No_PU_RD1_START53_V7N-v1/AODSIM
Physics process/Monte Carlo sample
DYJetsToLL_M-50_TuneZ2Star_8TeV-madgraph-tarball is hard to understand at first glance, but if we take our time we might be able to intuit some of the meaning. This appears to simulate a Drell-Yan process in which two quarks interact to produce a virtual photon/Z boson which then couples to two leptons. The M-50 refers to a selection that has been imposed requiring the mass of the di-lepton pair to be above 50 GeV/c^2 and the remaining fields tell us something about what software was used to generate this (madgraph) the beam energy (8TeV) and some extra, quite frankly, Byzantine text. :)
Global tag
Summer12_DR53X-No_PU_RD1_START53_V7N-v1 refers to how and when this Monte Carlo was processed. The details are not so important for you because the open data coordinators have taken care to only post vetted data. But it is all part of the data provenance.
Data format
The last field refers to the data format and here again there is a slight difference.
- AODSIM or MINIAODSIM stands for Analysis Object Data - Simulation. This is the same as the AOD or MINIAOD format used in the collision data, except that there are some extra fields that store information about the original, generated 4-vectors at the parton level, as well as some other Monte Carlo-specific information.
One difference is that you will want to select the Monte Carlo events that pass certain triggers at the time of your analysis, while that selection was already done in the data by the detector hardware/software itself.
If you click on any of these fields, you can see more details about the samples, similar to the collision data.
More Monte Carlo samples
If you would like a general idea of what other physics processes have been simulated, you can check scroll down the sidebar until you come to Filter by category.
CERN Open Data Portal - CMS datasets
Selection of the Monte Carlo dataset search options
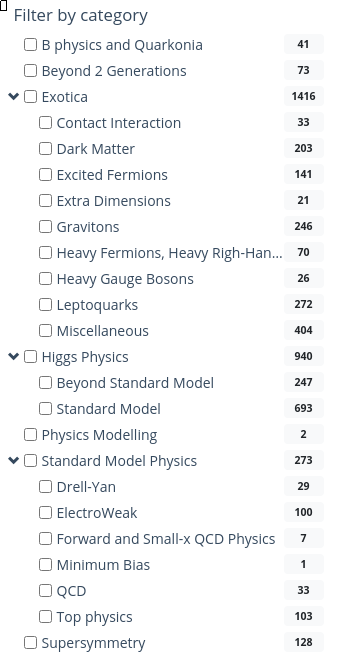
You may have to do a bit of poking around to find the dataset that is most appropriate for what you want to do, but remember, you can always reach out to the organizers through Mattermost.
Summary
By now you should have a good sense of how to find your data using the Open Data Portal’s search tools.
Key Points
The collision data are directed to different datasets based on trigger decisions
The Monte Carlo datasets contain a specific simulated physics process
How to access metadata on the command line?
Overview
Teaching: 5 min
Exercises: 5 minQuestions
What is cernopendata-client?
How to use cernopendata-client container image?
How to get the list of files in a dataset on the command line?
Objectives
To be able to access the information programmatically
Dataset information
Each CMS Open Data dataset comes with metadata that describes its contents (size, number of files, number of events, file listings, etc) and provenance (data-taking or generator configurations, and information on reprocessings), or provides usage instructions (the recommended CMSSW version, Global tag, container image, etc). The previous section showed how this information is displayed on the CERN Open Data portal. Now we see how it can also be retrieved programmatically or on the command line.
Command-line tool
cernopendata-client is a command-line tool to download files or metadata of CERN Open Data portal records. It can be installed with pip or used through the container image.
As you already have Docker installed, we use the latter option. Pull the container image with:
docker pull docker.io/cernopendata/cernopendata-client
Display the command help with:
docker run -i -t --rm docker.io/cernopendata/cernopendata-client --help
Usage: cernopendata-client [OPTIONS] COMMAND [ARGS]...
Command-line client for interacting with CERN Open Data portal.
Options:
--help Show this message and exit.
Commands:
download-files Download data files belonging to a record.
get-file-locations Get a list of data file locations of a record.
get-metadata Get metadata content of a record.
list-directory List contents of a EOSPUBLIC Open Data directory.
verify-files Verify downloaded data file integrity.
version Return cernopendata-client version.
This is equivalent to running cernopendata-client --help, when the tool is installed with pip. The command runs in the container, it displays the output and exits. Note the flag --rm: it removes the container created by the command so that they are not accumulated in your container list each time you run a command.
Get dataset information
Each dataset has a unique identifier, a record id (or recid), that shows in the dataset URL and can be used in the cernopendata-client commands.
For example, in the previous sections, you have seen that file listings are in multiple text files. To get the list of all files in the /SingleMu/Run2012B-22Jan2013-v1/AOD dataset, use the following (recid of this dataset is 6021):
docker run -i -t --rm docker.io/cernopendata/cernopendata-client get-file-locations --recid 6021 --protocol xrootd
or pipe it to a local file with:
docker run -i -t --rm docker.io/cernopendata/cernopendata-client get-file-locations --recid 6021 --protocol xrootd > files-recid-6021.txt
Explore other metadata fields
See how to get the metadata fields in JSON format with
docker run -i -t --rm docker.io/cernopendata/cernopendata-client get-metadata --recid 6021Note that the JSON format can be displayed in the CERN Open data portal web interface by adding
/export/jsonin the dataset URL. Try it!
Summary
cernopendata-client is a handy tool for getting dataset information programmatically in scripts and workflows.
We will be working on getting all metadata needed for an analysis of CMS Open Data datasets retrievable through cernopendata-client, and some improvements are about to be included in the latest version. Let us know what you would like to see implemented on Mattermost!
Key Points
cernopendata-client is a command-line tool to download dataset files and metadata from the CERN Open Data portal.
What is in the datafiles?
Overview
Teaching: 5 min
Exercises: 5 minQuestions
How do I inspect these files to see what is in them?
Objectives
To be able to see what objects are in the data files
To be able to see how big these files are and how much space these object take up.
This part of the lesson will be done from within the CMSSW docker container. All commands will be typed inside that environment.
Go to your CMSSW area
If you completed the lesson on Docker you should already have a working CMSSW area, if your operating system allows.
Restart your existing my_od container with:
docker start -i my_od
Make sure you are in the CMSSW_7_6_7/src area; if needed change the directory:
cd /code/CMSSW_7_6_7/src
edmXXX tools
CMS uses a set of homegrown tools to interact with the AOD format, all of which are prefixed by edm, which stands for Event Data Model. We will not show you all of them, but introduce a few to give you an idea of what can be done.
edmDumpEventContent
The edmXXX tools take as an argument the full path to a file. Following a similar approach to the previous module, we’ve chosen one of the Monte Carlo files to test, but these commands would equally well with a data file.
Let’s start by using edmDumpEventContent and looking at the options
edmDumpEventContent --help
Usage: edmDumpEventContent [options] templates.root
Prints out info on edm file.
Options:
-h, --help show this help message and exit
--name print out only branch names
--all Print out everything: type, module, label, process, and
branch name
--lfn Force LFN2PFN translation (usually not necessary)
--lumi Look at 'lumi' tree
--run Look at 'run' tree
--regex=REGEX Filter results based on regex
--skipping Print out branches being skipped
--forceColumns Forces printouts to be in nice columns
We will first use edmDumpEventContent to see what is in one of these files with no other options. It may take 15-60 seconds to run and
there will be a lot of output. You may find it useful to redirect the output to a file and then look at it there
using less or a similar command (you can exit less by typing q).
edmDumpEventContent root://eospublic.cern.ch//eos/opendata/cms/mc/RunIIFall15MiniAODv2/DYJetsToLL_M-5to50_TuneCUETP8M1_13TeV-madgraphMLM-pythia8/MINIAODSIM/PU25nsData2015v1_76X_mcRun2_asymptotic_v12-v1/00000/029FD4E8-26DE-E511-92E9-0CC47A78A45A.root > test_edm_output.log
less test_edm_output.log
Type Module Label Process
----------------------------------------------------------------------------------------------
LHEEventProduct "externalLHEProducer" "" "LHE"
GenEventInfoProduct "generator" "" "SIM"
edm::TriggerResults "TriggerResults" "" "SIM"
edm::TriggerResults "TriggerResults" "" "HLT"
HcalNoiseSummary "hcalnoise" "" "RECO"
L1GlobalTriggerReadoutRecord "gtDigis" "" "RECO"
double "fixedGridRhoAll" "" "RECO"
double "fixedGridRhoFastjetAll" "" "RECO"
.
.
.
vector<reco::GenJet> "slimmedGenJets" "" "PAT"
vector<reco::GenJet> "slimmedGenJetsAK8" "" "PAT"
vector<reco::GenParticle> "prunedGenParticles" "" "PAT"
vector<reco::GsfElectronCore> "reducedEgamma" "reducedGedGsfElectronCores" "PAT"
vector<reco::PhotonCore> "reducedEgamma" "reducedGedPhotonCores" "PAT"
vector<reco::SuperCluster> "reducedEgamma" "reducedSuperClusters" "PAT"
vector<reco::Vertex> "offlineSlimmedPrimaryVertices" "" "PAT"
vector<reco::VertexCompositePtrCandidate> "slimmedSecondaryVertices" "" "PAT"
unsigned int "bunchSpacingProducer" "" "PAT"
You can get from this information the names of physics objects you may be interested in (e.g. slimmedGenJets)
as well as what stage of processing they were produced at (SIM is for simulations, RECO is for reconstruction and PAT is for MINIAOD level).
This information can be useful when writing your analysis code, which will be discussed in a later lesson.
Some of the other command-line options can be useful as well to filter the information.
Challenge!
Try the following options (with the same file) and see what it gives you. Can you see why this might be useful?
edmDumpEventContent --regex=Muon root://eospublic.cern.ch//eos/opendata/cms/mc/RunIIFall15MiniAODv2/DYJetsToLL_M-5to50_TuneCUETP8M1_13TeV-madgraphMLM-pythia8/MINIAODSIM/PU25nsData2015v1_76X_mcRun2_asymptotic_v12-v1/00000/029FD4E8-26DE-E511-92E9-0CC47A78A45A.root edmDumpEventContent --name root://eospublic.cern.ch//eos/opendata/cms/mc/RunIIFall15MiniAODv2/DYJetsToLL_M-5to50_TuneCUETP8M1_13TeV-madgraphMLM-pythia8/MINIAODSIM/PU25nsData2015v1_76X_mcRun2_asymptotic_v12-v1/00000/029FD4E8-26DE-E511-92E9-0CC47A78A45A.root
Key Points
It’s useful to sometimes inspect the files before diving into the full analysis
Some files may not have the information you’re looking for
Hands-on activity
Overview
Teaching: 0 min
Exercises: 15 minQuestions
How well do you understand what we covered?
Objectives
To review…
Let’s review some of the concepts we covered in the previous episodes. You are encouraged to go back and engage with those episodes in order to answer these questions.
Let’s review!
Can you get to the starting page for the CMS Open Data Portal? Can you select the CMS data from that page?
Let’s review!
The bulk of the CMS released data covers what years? What was the collision energy for those years?
Let’s review!
What’s the difference between Collision data and Simulated data?
Let’s review!
Select the CMS collision data for 2015. Select only the MINIAOD data. Do you remember what the MINIAOD data are?
Choose one dataset and identify different triggers that were used to direct events in this dataset. What do you think they are triggering on?
Let’s review!
Select the CMS simulated data for 2015. Select the Heavy Gauge Bosons (under Filter by category) and find a Wprime sample. Click on it. These are hypothetical gauge bosons.
How can you learn about CMS simulated dataset names? What do you think the W’ is decaying to? What is the assumed mass of the W’ in this particular sample?
How many events are in this sample? How much hard drive space does this sample occupy? Can you find the generator parameters that were used to generate the collisions?
Key Points
The information is all there for you to find datasets you want for your analysis.
But it make take some poking around to find it.
Familiarizing yourself with the search options is time well-spent.