Introduction
Overview
Teaching: 5 min
Exercises: 5 minQuestions
How to get to your cluster?
How to get ready to submit the workflow?
Objectives
Get your GCP environment ready to run an argo workflow
Scale your cluster up to 4 nodes
Get the tools running to observe the working processes
Access your GKE Cluster
For the CMS-Workshop 2022 we have added you to a GCP project where we will provide temporary resources to run an Argo Workflow. Before we get into details please follow the following steps to get things started!
Find your cluster
- Go to the Google Cloud Console and login with your google account.
- Verify that you are in the CMS-opendata Project.

- Go the Kubernetes engines cluster listing from the Navigation menu top left, scroll down to “Kubernetes engine” and select “Clusters”.

- Find the number of your cluster in the email you have received and select your cluster in the list.
Resize your cluster
The cluster has been created with one node only to limit the costs. Now as you start using the cluster, resize your cluster to 4 nodes:
- Click on the three vertical dots after your cluster name and select “Edit”.

- Choose Nodes.

- Then click on the Node pools name “terraform…”.
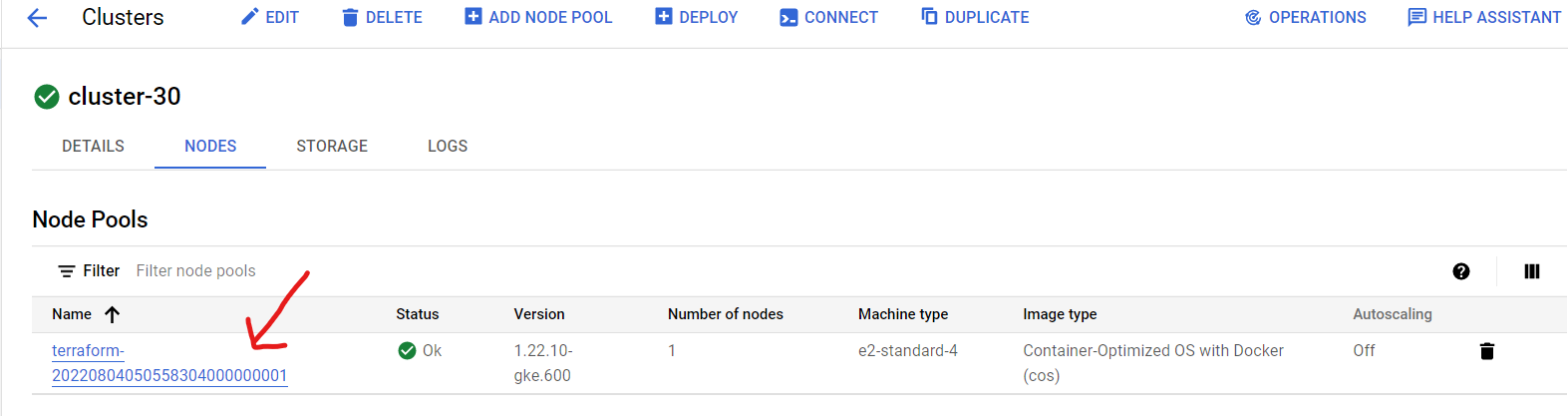
- Select “Resize”.
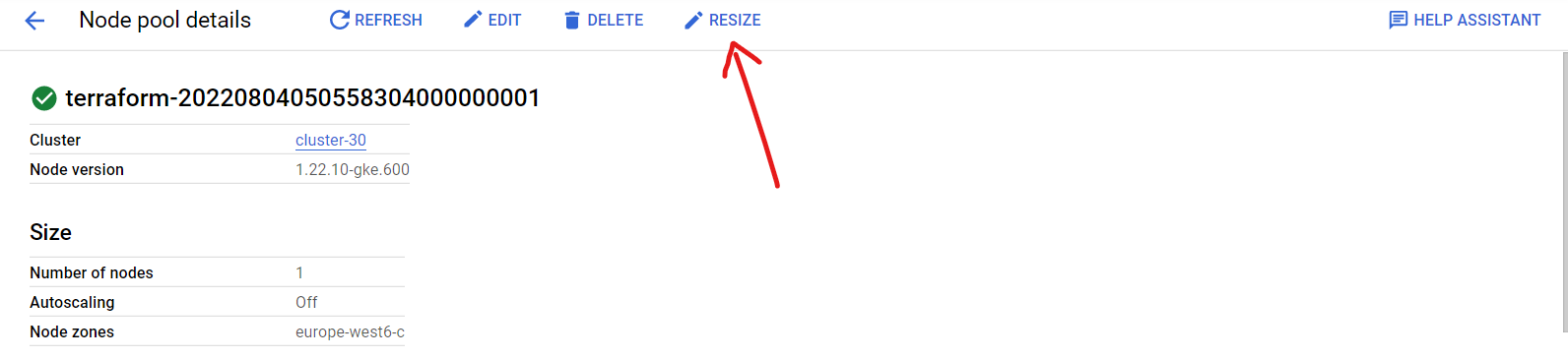
- Set the number of nodes to 4.

Connect to the cluster
- Now go back to the cluster listing page, click on the three vertical dots and choose connect.

- Click on “RUN IN CLOUD SHELL” to connect to your cluster.

- In the cloud shell press Enter after the command and authorize cloud shell in the pop-up window that opens

- If requested, submit the command
gcloud auth loginand follow the link the get the authorization code.
Argo
Argo command-line interface
Argo components are already running on the cluster! But to submit the workflow from the cloud shell, you will need the argo command-line interface. You can download the binary and move it to it’s respective path with the following commands:
curl -sLO https://github.com/argoproj/argo-workflows/releases/download/v3.4.7/argo-darwin-amd64.gz
gunzip argo-linux-amd64.gz
chmod +x argo-linux-amd64
sudo mv ./argo-linux-amd64 /usr/local/bin/argo
Submit the workflow
Now fast forward: to make sure that the workflow makes it in time to finish during the hands-on session, submit it right now. We will explain the details while the workflow is running.
Get the workflow file with
wget https://raw.githubusercontent.com/cms-opendata-analyses/PhysObjectExtractorTool/odws2022-ttbaljets-prod/PhysObjectExtractor/cloud/argo-poet-ttbar.yaml
The workflow defines the persistent volume in which the output is stored. Edit the workflow to replace <NUMBER> to correspond to your cluster number.
nano argo-poet-ttbar.yaml
Then submit the workflow with
argo submit argo-poet-ttbar.yaml -n argo
Check that it got running with
argo get @latest -n argo
Get your services
Your cluster has been built altogether with Terraform, including all the configurations seen in the cloud pre-exercises.
To get the external IP of both the Argo GUI (with which you can follow the workflow) and the http server (through which you can download the ouputs), run the following command:
kubectl get svc -n argo
Http File Server
In a new tab open <EXTERNAL-IP>, no need to add anything, just paste the external IP of your http-fileserver-<NUMBER> from the ouput of the command above.
Argo GUI
In a new tab open https://<EXTERNAL-IP>:2746, replacing <EXTERNAL-IP> with corresponding external IP of your argo-server-<NUMBER> from the ouput of the command above.
Next
OK, we got it running! Now let’s go to see the details…
Key Points
You can submit the workflow from the Google cloud shell connected to your cluster.